Welcome to My Blog
每天进步一点点-
Kubernetes默认调度器的优先级与抢占机制
在上一篇文章中,详细讲解了 Kubernetes 默认调度器的主要调度算法的工作原理。在本篇文章中,来讲解一下 Kubernetes 调度器里的另一个重要机制,即:优先级(Priority )和抢占(Preemption)机制。
首先需要明确的是,优先级和抢占机制,解决的是 Pod 调度失败时该怎么办的问题。
正常情况下,当一个 Pod 调度失败后,它就会被暂时“搁置”起来,直到 Pod 被更新,或者集群状态发生变化,调度器才会对这个 Pod 进行重新调度。
但在有时候,我们希望的是这样一个场景:当一个高优先级的 Pod 调度失败后,该 Pod 并不会被“搁置”,而是会“挤走”某个 Node 上的一些低优先级的 Pod 。这样就可以保证这个高优先级 Pod 的调度成功。这个特性,其实也是一直以来就存在于 Borg 以及 Mesos 等项目里的一个基本功能。
-
Kubernetes的默认调度策略解析
在上一篇文章中,主要讲解了 Kubernetes 默认调度器的设计原理和架构。在今天这篇文章中,我们就专注在调度过程中 Predicates 和 Priorities 这两个调度策略主要发生作用的阶段。
Predicates
Predicates 在调度过程中的作用,可以理解为 Filter,即:它按照调度策略,从当前集群的所有节点中,“过滤”出一系列符合条件的节点。这些节点,都是可以运行待调度 Pod 的宿主机。
而在Kubernetes中,默认的调度策略有如下几种。
-
Kubernetes的默认调度器
Kubernetes的默认调度器
在Kubernetes项目中,默认调度器(default scheduler)的主要职责,就是为一个新创建出来的Pod,寻找到一个最合适的节点(Node)。
而这里“最合适”的含义,包括两层:
- 从集群所有的节点中,根据调度算法挑选出所有可以运行该 Pod 的节点;
- 从第一步的结果中,再根据调度算法挑选一个最符合条件的节点作为最终结果。
所以在具体的调度流程中,默认调度器会首先调用一组叫作 Predicate 的调度算法,来检查每个 Node。
然后,再调用一组叫作 Priority 的调度算法,来给上一步得到的结果里的每个 Node 打分。最终的调度结果,就是得分最高的那个 Node。
我们知道,调度器对一个 Pod 调度成功,实际上就是将该Pod的 spec.nodeName 字段填上调度结果的节点名字。
-
Kubernetes的资源模型与资源管理
资源模型
在 Kubernetes 里,Pod 是最小的原子调度单位。这也就意味着,所有跟调度和资源管理相关的属性都应该是属于 Pod 对象的字段。而这其中最重要的部分,就是 Pod 的 CPU 和内存配置,如下所示:
-
边缘计算与雾计算
最近在看 EC 和 Fog 方面的论文,发现很多论文都没有很好地区分这两个概念,往往是混为一谈的,仔细想想,我也感觉边缘与雾差别性不大,不是很好具体地区分。我又在网上收集了一些资料,总结为这篇博文,仅供参考。
边缘计算的各个定义
边缘计算与云计算一样,是一种计算的范式,更具体地说,是一种分布式的计算范式。
由于行业、技术背景等不同,边缘计算在不同人眼里是有一定差异的。我们先来看看不同专家是如何定义边缘的:
-
快速排序和堆排序
快速排序
我们知道冒泡排序、插入排序、选择排序这三种排序算法,它们的时间复杂度都是O(n2),比较高,只适合小规模的排序。归并排序和快速排序,是时间复杂度为O(nlogn)的排序算法,这两种排序算法就比较适合大规模的数据排序,且它们都用到了分治思想。
在实际的工程项目中,快排是最常用到的一种排序算法,所以本文将重点介绍快排。
快排的原理
快速排序算法(Quick Sort),我们习惯性把它简称为“快排”,快排利用的也是分治思想。我们先来看下快排的核心思想。快排的思想是这样的:
如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
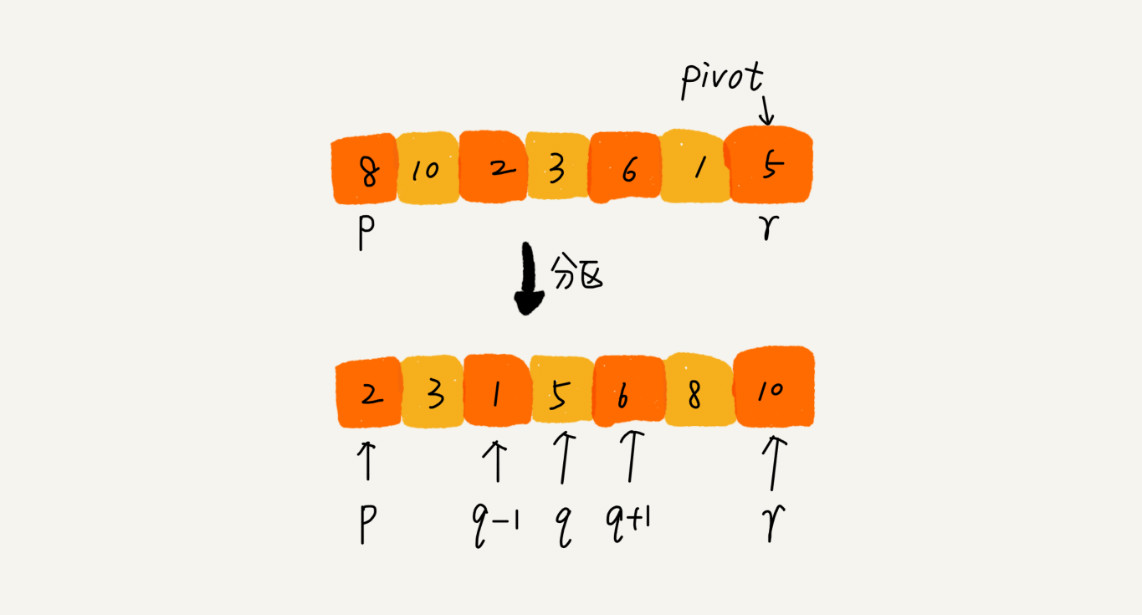
根据分治的处理思想,我们可以用递归来排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
- CRI 与 容器运行时
- Kubernetes 存储篇(3)— Local Persistent Volume
- Kubernetes 存储篇(2)— StorageClass
- Kubernetes 存储篇(1) — PV 与 PVC
- Kubernetes 网络篇(7)— Service 与 Ingress
- Kubernetes 网络篇(6)— Service实现集群外部访问
- Kubernetes 网络篇(5)— Service实现集群内部访问
- Kubernetes 网络篇(4)— host-gw与Calico
- Kubernetes 网络篇(3)— CNI网络插件
- Kubernetes 网络篇(2)— Flannel