在 Kubernetes 完成对 Pod 的调度后,下一步就需要负责将这个调度成功的 Pod 在宿主机上创建起来,同时把 Pod 对应的各个容器启动起来。这些功能的实现正是 kubelet 这个核心组件的任务。
kubelet
在 Kubernetes 社区里,与 kubelet 以及容器运行时管理相关的内容都属于 SIG-Node 的范畴。SIG-Node 以及 kubelet 其实是 Kubernetes 整套体系里非常核心的一个部分,毕竟它们才是 Kubernetes 这个容器编排与管理系统与容器打交道的主要方式。而 kubelet 这个组件本身也是 Kubernetes 里面第二个不可被替代的组件(第一个不可被替代的组件当然是 kube-apiserver)。也就是说,无论如何都不建议用户对 kubelet 的代码进行大量的改动,保持 kubelet 跟上游基本一致的重要性就跟保持 kube-apiserver 跟上游一致是一个道理。
kubelet 本身也是按照控制器模式来工作的。它的工作原理如示意图所示:
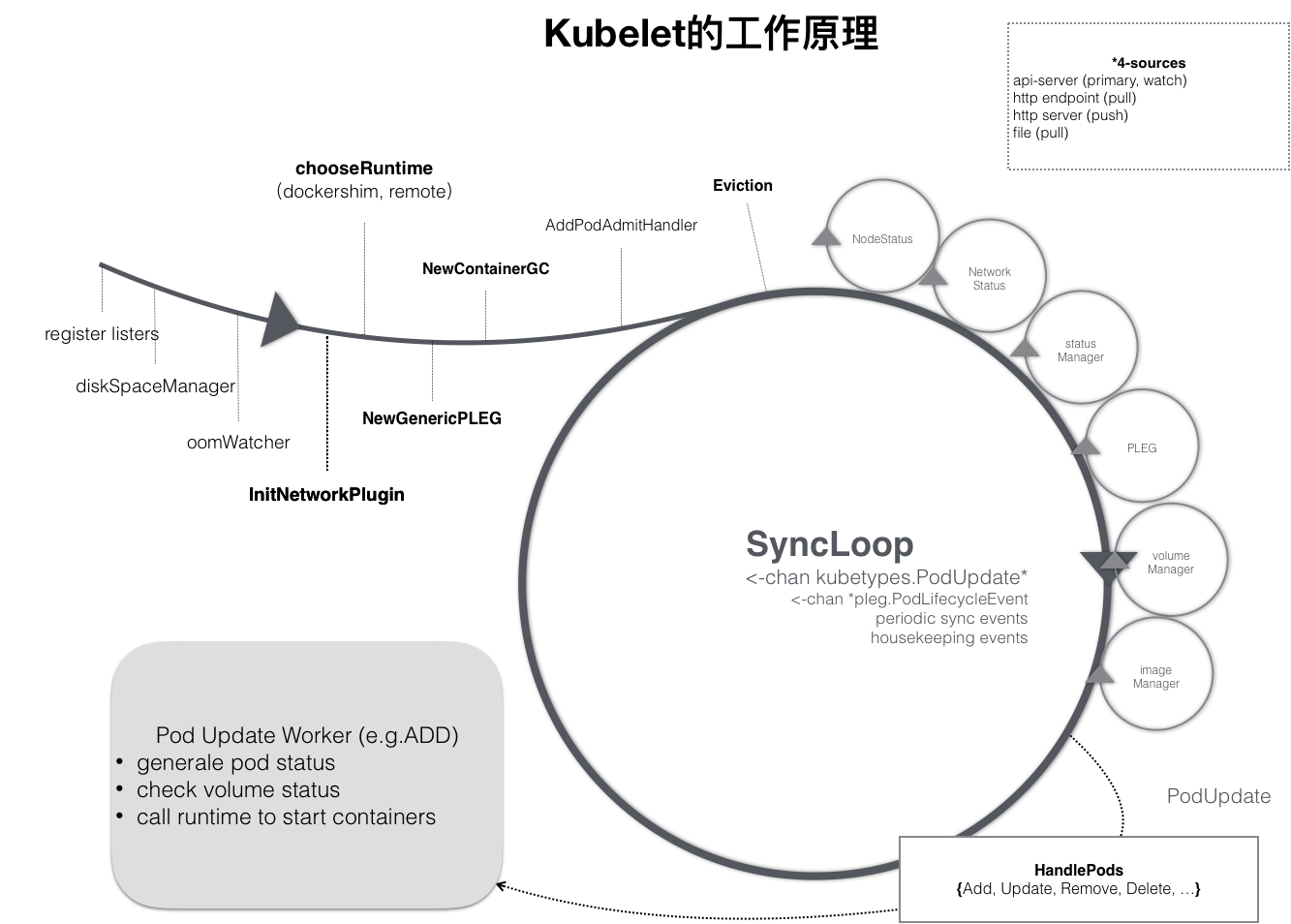
可以看到 kubelet 的工作核心就是一个控制循环,即:SyncLoop(图中的大圆圈)。而驱动这个控制循环运行的事件,包括四种:
- Pod 更新事件;
- Pod 生命周期变化;
- kubelet 本身设置的执行周期;
- 定时的清理事件。
跟其他控制器类似,kubelet 启动时要完成的第一件事就是设置 Listers,也就是注册它所关心的各种事件的 Informer。这些 Informer 就是 SyncLoop 需要处理的数据的来源。此外,kubelet 还负责维护着很多很多其他的子控制循环(也就是图中的小圆圈)。这些控制循环的名字一般被称作某某 Manager,比如 Volume Manager、Image Manager、Node Status Manager 等等。这些控制循环的责任就是通过控制器模式完成 kubelet 的某项具体职责,比如 Node Status Manager 就负责响应 Node 的状态变化,然后将 Node 的状态收集起来并通过 Heartbeat 的方式上报给 APIServer。再比如 CPU Manager 就负责维护该 Node 的 CPU 核的信息,以便在 Pod 通过 cpuset 的方式请求 CPU 核的时候能够正确地管理 CPU 核的使用量和可用量。
那么 SyncLoop 又是如何根据 Pod 对象的变化来进行容器操作的呢?
实际上,kubelet 是通过 Watch 机制监听着与自己相关的 Pod 对象的变化,这个 Watch 的过滤条件是该 Pod 的 nodeName 字段与自己是否相同,kubelet 会把这些 Pod 的信息缓存在自己的内存里。当一个 Pod 完成调度并与一个 Node 完成绑定之后, 这个 Pod 的变化就会触发 kubelet 在控制循环里注册的 Handler,也就是上图中的 HandlePods 部分。此时,通过检查该 Pod 在 kubelet 内存里的状态,kubelet 就能够判断出这是一个新调度过来的 Pod,从而触发 Handler 里 ADD 事件对应的处理逻辑。在具体的处理过程当中,kubelet 会启动一个名叫 Pod Update Worker 的单独 Goroutine 来完成对 Pod 的处理工作。如果是 ADD 事件的话,kubelet 就会为这个新的 Pod 生成对应的 Pod Status,检查 Pod 所声明使用的 Volume 是不是已经准备好,再调用下层的容器运行时(比如 Docker)开始创建这个 Pod 所定义的容器;而如果是 UPDATE 事件的话,kubelet 就会根据 Pod 对象具体的变更情况调用下层容器运行时进行容器的重建工作。
需要注意的是 kubelet 调用下层容器运行时的执行过程并不会直接调用 Docker 的 API,而是通过一组叫作 CRI(Container Runtime Interface,容器运行时接口)的 gRPC 接口来间接执行的。Kubernetes 项目之所以要在 kubelet 中引入这样一层单独的抽象,是为了对 Kubernetes 屏蔽下层容器运行时的差异。实际上,对于 1.6 版本之前的 Kubernetes 来说,它就是直接调用 Docker 的 API 来创建和管理容器的。在 2016 年,SIG-Node 把 kubelet 对容器的操作统一地抽象成一个接口。这样,kubelet 就只需要跟这个接口打交道了。而作为具体的容器项目,比如 Docker、 rkt、runV,它们就只需要自己提供一个该接口的实现,然后对 kubelet 暴露出 gRPC 服务即可。
CRI
有了 CRI 之后,Kubernetes 的架构图如下所示:
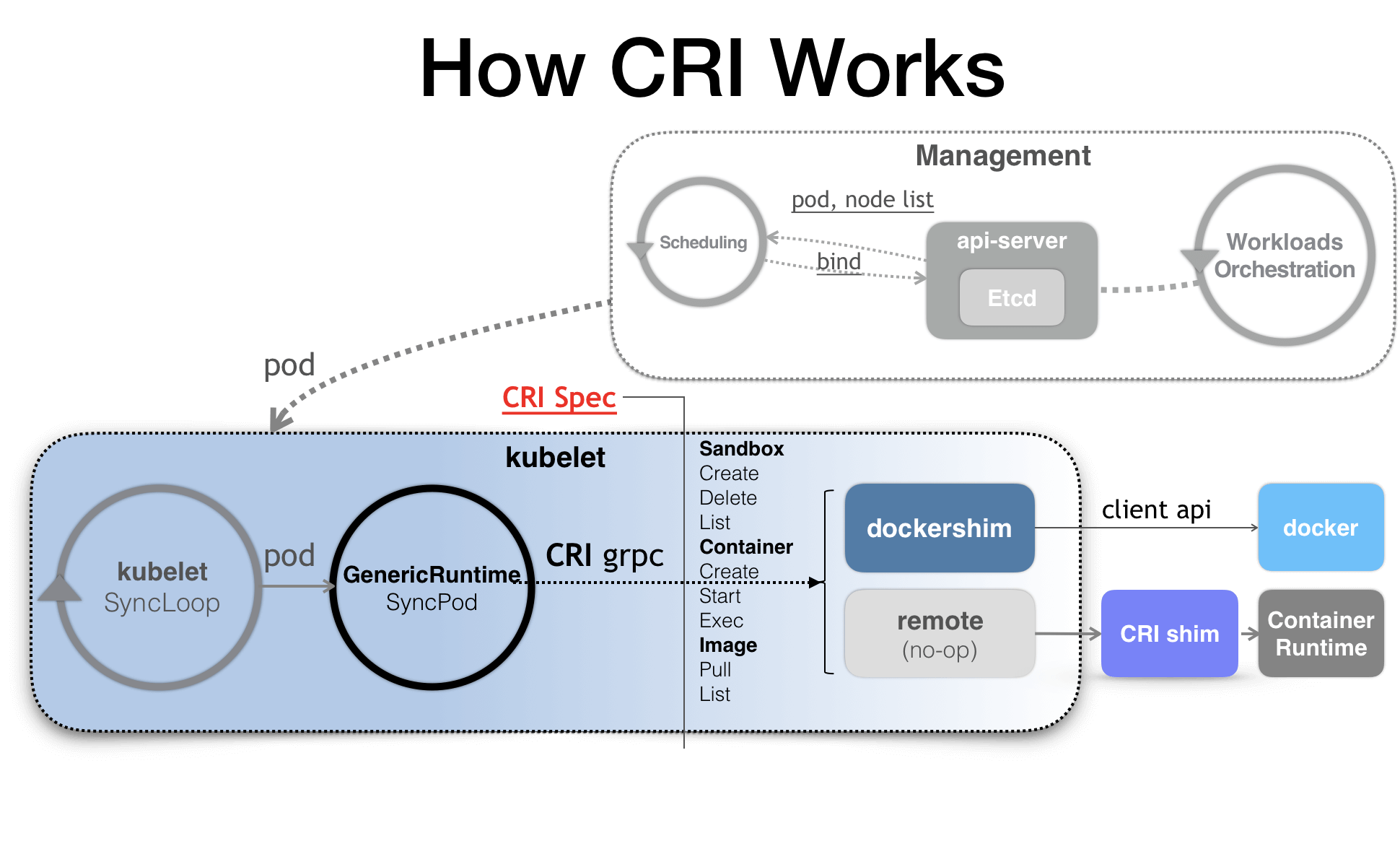
CRI 机制能够发挥作用的核心就在于每一种容器项目现在都可以自己实现一个 CRI shim,自行对 CRI 请求进行处理。这样,Kubernetes 就有了一个统一的容器抽象层,使得下层容器运行时可以自由地对接进入 Kubernetes 中,所以说 CRI shim 就是容器项目的维护者们自由发挥的“场地”了。
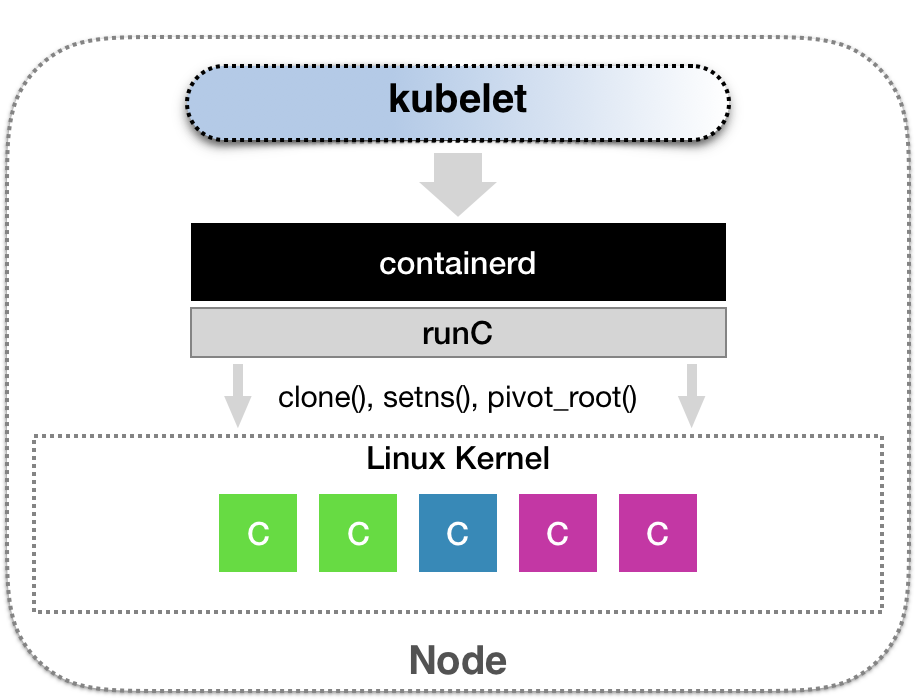
而除了 dockershim 之外,其他容器运行时的 CRI shim 都是需要额外部署在宿主机上的。举个例子,CNCF 里的 containerd 项目就可以提供一个典型的 CRI shim 的能力,即:将 Kubernetes 发出的 CRI 请求转换成对 containerd 的调用,然后创建出 runC 容器。而 runC 项目才是负责执行我们前面讲解过的设置容器 Namespace、Cgroups 和 chroot 等基础操作的组件。所以,这几层的组合关系可以用如下所示的示意图来描述:
作为一个 CRI shim,containerd 对 CRI 的具体实现,又是怎样的呢?下图展示了 CRI 接口的定义,即 CRI 中主要的待实现接口:
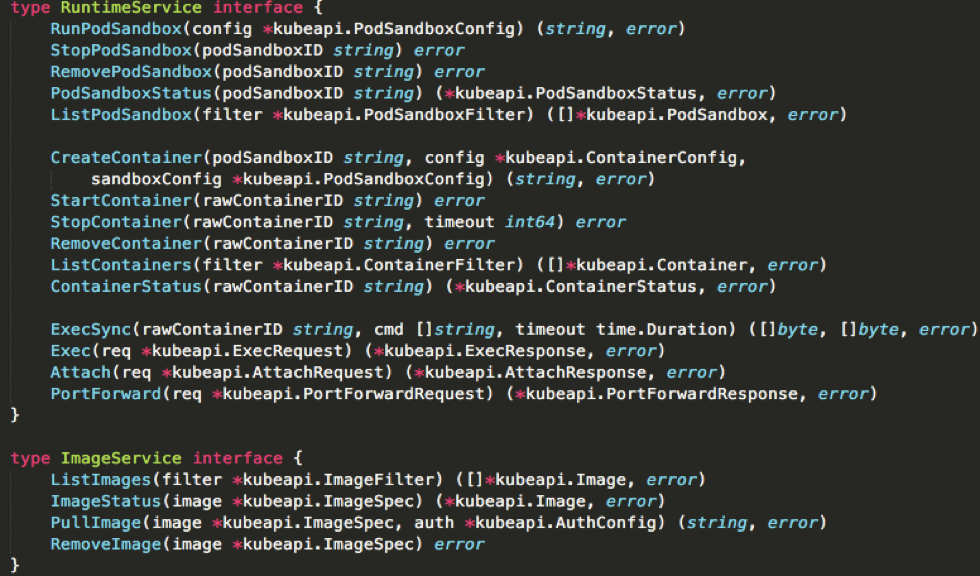
我们可以把 CRI 分为两组:
- 第一组,是 RuntimeService。它提供的接口主要是跟容器相关的操作。比如,创建和启动容器、删除容器、执行 exec 命令等等;
- 第二组,则是 ImageService。它提供的接口主要是容器镜像相关的操作,比如拉取镜像、删除镜像等等。
关于容器镜像的操作比较简单,所以这里就暂且略过,重点是 RuntimeService 部分。在 RuntimeService 部分,CRI 设计的一个重要原则就是确保这个接口本身只关注容器,不关注 Pod。原因是因为:
- 第一,Pod 是 Kubernetes 的编排概念,而不是容器运行时的概念,所以不能假设所有下层容器项目都能够暴露出可以直接映射为 Pod 的 API。
- 第二,如果 CRI 里引入了关于 Pod 的概念,那么接下来只要 Pod API 对象的字段发生变化,那么 CRI 就很有可能需要变更。而在 Kubernetes 开发的前期,Pod 对象的变化还是比较频繁的,但对于 CRI 这样的标准接口来说,这个变更频率就有点麻烦了。
所以,在 CRI 的设计里并没有一个直接创建 Pod 或者启动 Pod 的接口。
注意 CRI 里还有一组叫作 RunPodSandbox 的接口的。PodSandbox 对应的并不是 Kubernetes 里的 Pod API 对象,而只是抽取了 Pod 里的一部分与容器运行时相关的字段,比如 HostName、DnsConfig、CgroupParent 等。所以说 PodSandbox 这个接口描述的其实是 Kubernetes 将 Pod 这个概念映射到容器运行时层面所需要的字段,或者说是一个 Pod 对象子集。而作为具体的容器项目就需要自行去决定如何使用这些字段来实现一个 Kubernetes 期望的 Pod 模型。这里的原理可以用如下所示的示意图来表示:
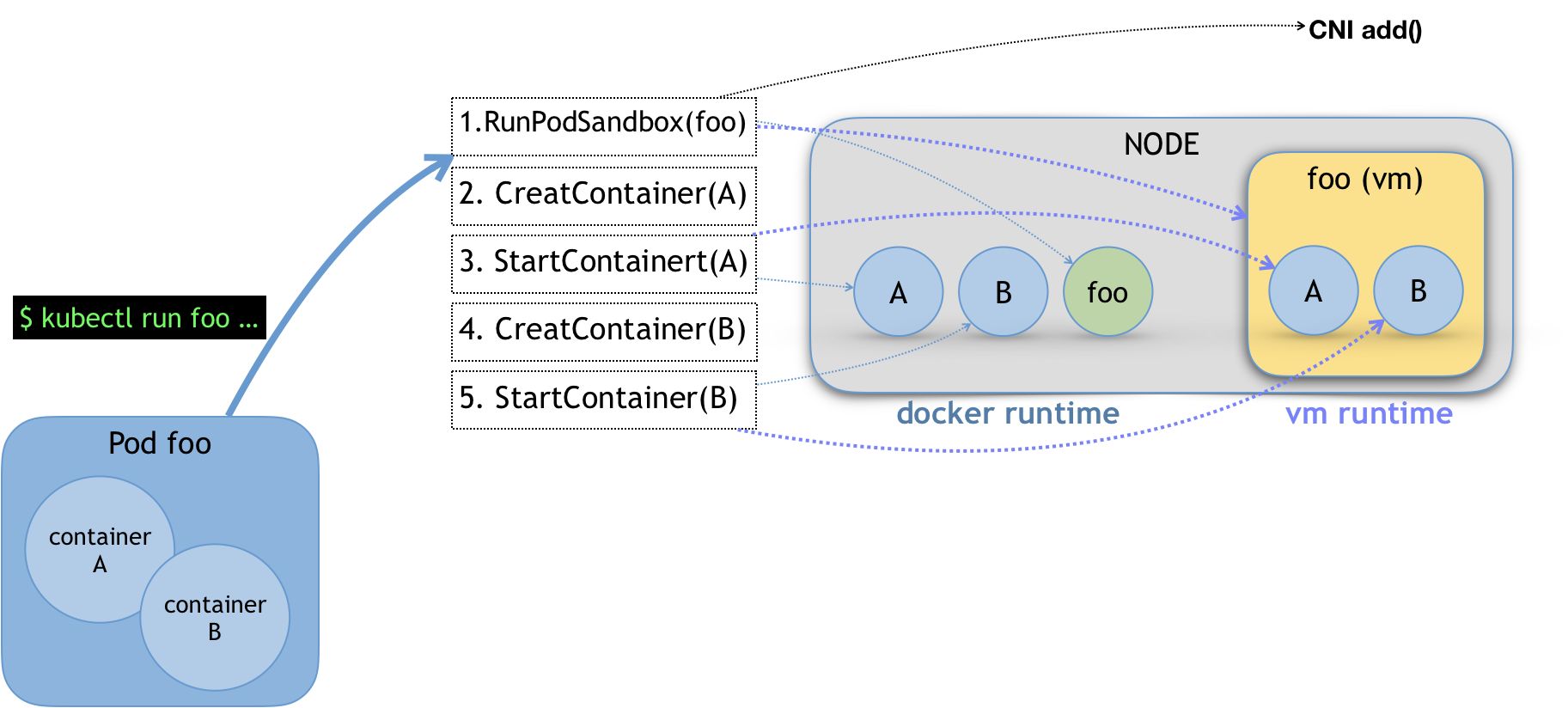
比如,当用户执行 kubectl run 创建了一个名叫 foo 的、包括了 A、B 两个容器的 Pod 之后,这个 Pod 的信息最后来到 kubelet,kubelet 就会按照图中所示的顺序来调用 CRI 接口。在具体的 CRI shim 中,这些接口的实现是可以完全不同的。比如,如果是 Docker 项目,dockershim 就会创建出一个名叫 foo 的 Infra 容器(pause 容器),用来“hold”住整个 Pod 的 Network Namespace。而如果是基于虚拟化技术的容器,比如 Kata Containers 项目,它的 CRI 实现就会直接创建出一个轻量级虚拟机来充当 Pod。
此外,在 RunPodSandbox 这个接口的实现中需要调用 networkPlugin.SetUpPod(…) 来为这个 Sandbox 设置网络。这个 SetUpPod(…) 方法,实际上就在执行 CNI 插件里的 add(…) 方法,也就是 CNI 插件为 Pod 创建网络并把 Infra 容器加入到网络中的操作。
接下来,kubelet 继续调用 CreateContainer 和 StartContainer 接口来创建和启动容器 A、B。对应到 dockershim 里,就是直接启动 A,B 两个 Docker 容器。所以最后,宿主机上会出现三个 Docker 容器组成这一个 Pod。而如果是 Kata Containers 的话,CreateContainer 和 StartContainer 接口的实现,就只会在前面创建的轻量级虚拟机里创建两个 A、B 容器对应的 Mount Namespace。所以,最后在宿主机上,只会有一个叫作 foo 的轻量级虚拟机在运行。
除了上述对容器生命周期的实现之外,CRI shim 还有一个重要的工作,就是如何实现 exec、logs 等接口。这些接口跟前面的操作有一个很大的不同,就是这些 gRPC 接口调用期间,kubelet 需要跟容器项目维护一个长连接来传输数据。这种 API,我们就称之为 Streaming API。CRI shim 里对 Streaming API 的实现,依赖于一套独立的 Streaming Server 机制,这一部分原理如下所示:
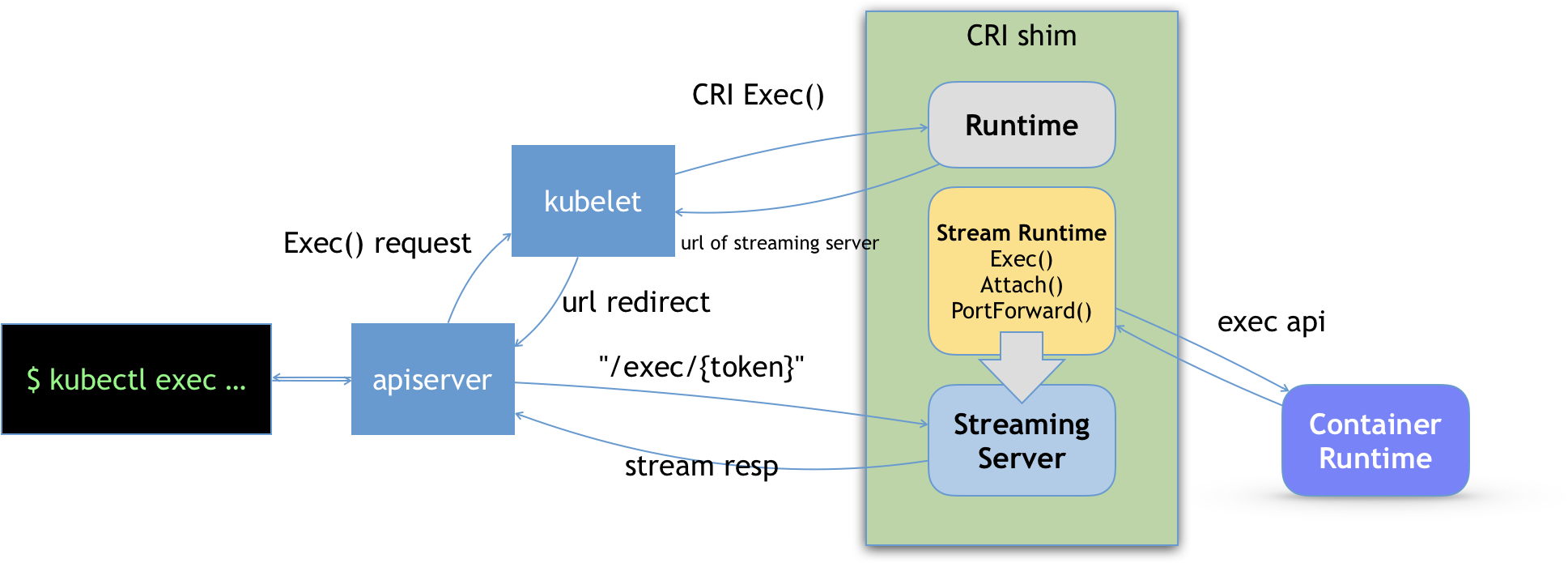
可以看到,当对一个容器执行 kubectl exec 命令的时候,这个请求首先交给 API Server,然后 API Server 就会调用 kubelet 的 Exec API,此时 kubelet 就会调用 CRI 的 Exec 接口,而负责响应这个接口的就是具体的 CRI shim。但在这一步,CRI shim 并不会直接去调用后端的容器项目(比如 Docker )来进行处理,而只会返回一个 URL 给 kubelet。这个 URL 就是该 CRI shim 对应的 Streaming Server 的地址和端口。kubelet 在拿到这个 URL 之后,就会把它以 Redirect 的方式返回给 API Server,API Server 会通过重定向来向 Streaming Server 发起真正的 /exec 请求并与它建立长连接。
当然,这个 Streaming Server 本身是需要通过使用 SIG-Node 维护的 Streaming API 库来实现的。并且,Streaming Server 会在 CRI shim 启动时就一起启动。此外,Stream Server 这一部分具体怎么实现,完全可以由 CRI shim 的维护者自行决定。比如,对于 Docker 项目来说,dockershim 就是直接调用 Docker 的 Exec API 来作为实现的。
以上,就是 CRI 的设计以及具体的工作原理了。
总结
本篇文章解读了 kubelet 和 CRI 的工作原理,不难看出 CRI 接口的设计实际上还是比较宽松的。这就意味着容器项目的维护者在实现 CRI 的具体接口时,往往拥有着很高的自由度。这个自由度不仅包括了容器的生命周期管理,也包括了如何将 Pod 映射成自己的实现,还包括了如何调用 CNI 插件来为 Pod 设置网络的过程。
所以说,当你对容器这一层有特殊的需求时,优先建议你考虑实现一个自己的 CRI shim ,而不是修改 kubelet 甚至容器项目的代码。这样通过插件的方式定制 Kubernetes 的做法,也是整个 Kubernetes 社区最鼓励和推崇的一个最佳实践。这也正是为什么像 Kata Containers、gVisor 甚至虚拟机这样的“非典型”容器,都可以无缝接入到 Kubernetes 项目里的重要原因。